
Organizations have more data available today than ever before, and data architects, analysts, and data scientists are becoming prevalent in all business functions. Yet as companies fight for skilled analyst roles to utilize data to make better decisions, they often fall short in improving the data supply chain and resulting data quality. Without a solid data supply-chain management practices in place, data quality often suffers.
Poor data quality is cited as the major reason initiatives fail to achieve their expected value – up to 60% of business initiatives fail because of data quality issues. Data quality becomes an even more pressing issue as organizations move toward AI/ML-enabled decision-making. If the data used to fuel AI/ML models is inaccurate, incomplete, or outdated, the models won’t deliver the desired outcomes.
Data is the key raw material for analytics and decision-making. Every effective business leader asks, “How do we improve data quality so the decisions we make are the best we can do?” The answer is to improve outcomes from a company’s data supply chain to ensure it is not a liability to analytics capabilities.
How might we improve the outcomes from our data supply chain?
- Understand first mile/last mile data impacts
- Reduce supply chain complexity / costs
- Improve monitoring and reporting of data quality
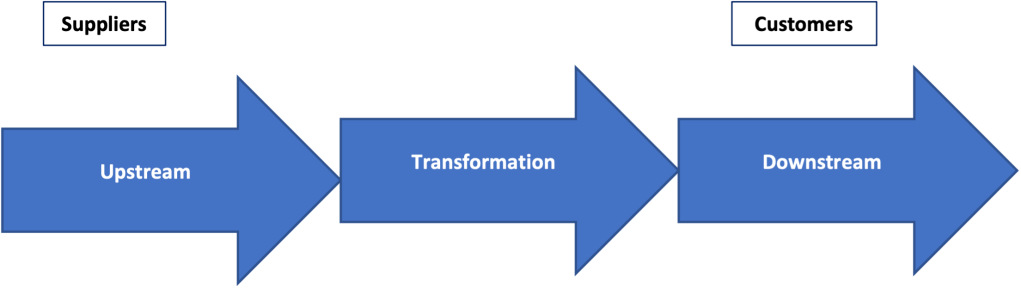
Supply chains are comprised of three major elements:
David Angelow
First mile/last mile impacts
The first mile / last mile challenge requires addressing the supply chain overall starting with sourcing the data (upstream). The urgency to have data available for analysis and decision-making drives firms to invest more effort in the “last mile” – getting data to the customer, downstream. In the case of the data supply chain the customer of course is an internal department or team needing the data for analysis, reporting, etc. The challenge is to capture source of the data correctly from the outset and ensure data quality does not degrade when moving across the data supply-chain.
A key supply chain management metric used to evaluate the performance of physical supply chains is OTIF – On-Time-In-Full. While a strange acronym, improving the value has dramatic results because it directly relates to the end-customer and their ability to perform their job. For example, if you need 10 attributes to generate a customer satisfaction score yet only 9 are available, the calculation cannot be performed. Utilizing a metric that focuses on the impact of data quality and availability to downstream processes can help sharpen organizational awareness.
- Recommended action plan: Create a map of your data supply chain. The concept of supply chain visibility and sourcing applies to data supply chains just as well as physical supply chain management. Understanding the sources of data, any transformation activities that take place as well as the “customer lead time” helps organizations identify and mitigate risks. Implementing metrics to evaluate how well the organization is meeting customer needs helps sharpen improvement focus.
Supply chain complexity
Supply chain complexity is the term used to describe the network of capabilities needed to fulfill downstream needs. The greater the number of suppliers, business functions, and distributors needed, the greater the complexity.
Each additional element in the supply chain increases complexity, and more complexity contributes to increased variability. Variability is a major challenge in quality. In physical supply chains, organizations seek to reduce upstream complexity. In the data supply chain, there are a variety of sources of internal and external data (from data brokers, social media/sentiment analysis, etc.) and just like a physical supply chain, reducing complexity in the data supply chain helps improve overall quality.
How can reducing complexity improve the quality? Fewer systems means fewer data transformations, which increases the availability and accuracy of data.
- Recommended action plan: Inventory the data available for downstream use and map to the source system (internal vs external). Frequently, common attributes are created in more than one system, which increases complexity. For each data element, identify/select a single system for downstream consumption and establish a “system of record” (SOR) with the goal of obtaining data from as few of systems as possible.
Data monitoring and reporting
Data quality should be a key performance indicator (KPI) for most every company today. The quality of outputs is dependent on the quality of the input. Think of every great meal you have ever had and what made it great; certainly, the company and ambience of the setting matters, yet the quality of the ingredients directly impacts the outcome – fresh-caught seafood always beats fresh-frozen.
The methods and frequency of evaluating data quality often varies within a firm. Different functions in an organization may use different methods to evaluate quality; accounting may be more stringent than marketing, for example. Yet why should different functions be evaluated differently? Good decision-making relies on quality data, and shouldn’t every function be making the best decision possible?
- Recommended action plan: Establish a common formula for measuring data quality and utilize the measurement consistently across all functions (data quality score). The volume of data to evaluate mandates sampling and estimating, and the approach should be consistent. An approach can be to sample 100 records, review each and identify any errors, then count the error-free records to understand the percent of data created correctly.
The data supply chain is an emerging and evolving concept for many organizations. Finding and retaining talent to help improve data supply chain outcomes is critical to a firm’s competitive advantage. Certainly, there are differences between tangible and intangible products, yet many of the concepts and tools from the physical world can be applied to data, and the result will be as impactful as improving physical supply chains.
Do not wait to get started.